


扇風機の異常動作検出
ディープラーニング技術を使用して、工場環境で異常検出を行うプロジェクトでした。私は、最適な機械学習手法の調査、学習データの収集、検証およびお客様へのデモンストレーションプログラムの準備を担当していました。工場環境で異常なデータを収集するのは容易ではないという現状を考慮し、まず、教師なし学習アルゴリズムのVAE 生成モデルを試しました。また、異常検出には、isolated forestというクラスタリング手法も使用しましたが、教師なし学習アルゴリズムの検出効果が満足できなかった(約60%の精度)ため、教師あり学習である分類モデルを構築するためにVGG16学習済み モデルのfinetuneも使用し、98%の精度に達成できました。
Tools: Python3, Keras, GCP, Matplotlib, Pandas, Flask, Kafka, OpenCV

下水浄化の予測と分析
オフィスビルなどの下水道の排水のため、下水タンクの水は定期的に浄化する必要があります。下水を浄化するために必要な浄化剤の量は、事業者の経験に依存し、天候などの外部の制御不可能な要因に関連しています。投入量が少なすぎると浄化効果が得られず、投資が多すぎると臭気が発生します。本プロジェクトでは、機械学習技術を使用して、浄化剤の投入量をモデル化し、自動的に予測しました。私はプロジェクトの進捗状況について議論するために、クライアントとの定期的な会議に参加しました。お客様のビジネスデータは、統計的手法を使用して分析し、毎週お客様に報告しました。適切な特徴量をデータから選定し、線形回帰、決定木などの機械学習手法を提案しました。ウェブスクレイピングで他社が公開しているデータを取得し特徴量としました。またクラスタリングを使用して未知の特徴量をマイニングしました。最後に、お客様の要件に応じて、お客様のビジネスプロセス自動化のため、簡易なアプリケーションも提供しました。
Tools: Python3, Matplotlib, Pandas, Scikit-learn, Jupyter Notebook, Git, Docker

知識データベースと知識獲得システムの提案
データ解析ビジネス拡大のために、自社製品としてグラフデータベース(Neo4j)を中心に知識データベースシステムを考案し、設計、検証を行いました。PoCとして会社のブログを自然言語処理によりNeo4jインポートしますが、トピックモデルを使用してブログ内のトピックをクラスター化し、知識グラフを作成しました。また、知識グラフを検索する際にCypherクエリを書く必要がなく、自然言語の問合せを形態素解析、格解析などによりCypherクエリを自動生成する仕組みを作りました。全文検索とは異なり、本プロジェクトの目的は、データベースから正確な結果を照会することではなく、知識グラフに存在する未発見の潜在的な知識を検索することです。
Tools: Python3, Neo4j, WordNet, Gensim, Cabocha
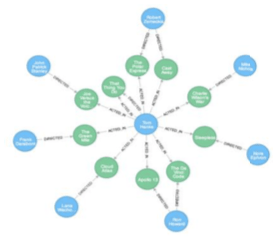
ユーザ行動分析基盤システムの構築
グラフデータベース(Neo4j)を使用して、行動分析のための基本システムを構築しました。お客様の社内データはAWS 上に保管されるため、本システムもAWS 上に構築しました。毎週の作業進捗をお客様に報告し、プロジェクトの進め方等について議論しました。お客様が購入した他の会社のマーケティングデータを使うことで、お客様が所有しないユーザの他属性も分析できるということで、データのマージ方法を検討、実装をしました。
Tools: Python3, Pandas, Apache Spark, Docker, AWS

スマートメーター管理システムの開発
このシステムは電力会社向けのシステムであり、電力会社が使うスマートメーターの仕様に合わせて開発を行いました。都市の隅々に分布するスマートメータを一つのシステムで操作できるシステムです。電力会社のオペレーターがユーザに訪問する必要がなく、リモートでメーターを操作でき、電力会社のコストダンに繋がります。本システムはメーターからのデータの収集、スイッチのオン/オフ、指定された期間のスイッチのオン/オフを含む一連のリモート操作を提供します。またネットワーク等の原因で欠測が発生した場合の再計測機能もあります。三菱電機の開発現場に常駐し、三菱電機のエンジニアとスマートメーター管理システムを設計および開発を行いました。
Tools: Java, Struts, Spring, Hibernate, JPA, dHtmlx, JQuery, Oracle, VoltDB, Javascript

ソフトウェアオフショア開発
日本向けのソフトウェア開発です。オフショアプロジェクトの中下流工程のため、プロジェクトは詳しく説明しません。私は開発現場で3〜4 人のチームを率いて開発を行いました。またBSE として行動し、日本の開発チームとコミュニケーションを取り、日本側の仕様変更などをチームメンバにフィードバックし、チームメンバの質問を日本側に連絡することを担当しました。プログラミング、テスト、レビューも担当しました。
Tools: Java, Struts, Spring, Hibernate, iBatis, Oracle, JQuery, PowerCenter

日本語文書からQ&Aを自動生成してみました #NLP
クリエションラインの朱です。主に機械...

Apache Mahoutでレコメンドエンジン(Correlated Cross-Occurrenceアルゴリズム)を試作
こんにちは、クリエーションラインの朱...

ディープラーニングでBitcoinの価格を予測して見る #Deep Learning #Keras
こんにちは、クリエーションラインの朱...

Docker、Jupyter Notebook、VCSツールで機械学習のチーム開発
こんにちは、クリエーションラインの朱...

天気データのみで電力を予測する:線形回帰編
こんにちは、クリエーションラインの朱...